Chapter 3 World open data
Several inter-governmenatal organizations have statisics divisions working in dissiminating global statistical information and maintaining open data plateforms. The main inter-governmental organization working in promoting open data is the united nations. It includes various specialized agencies such as the World Bank Group, the World Health Organization, the World Food Program, UNESCO… This chapter presents an overview of data produced and published by these organization and lists various sources of open data within different thematics.
3.1 Sources
3.1.1 United Nations
The United Nations (UN) is an intergovernmental organization that aims to maintain international peace and security, develop friendly relations among nations, achieve international cooperation, and harmonize their actions. The UN system includes a multitude of specialized agencies, such as the World Bank Group, the World Health Organization, the World Food Programme, UNESCO, and UNICEF. The United Nations Statistics Division is committed to the advancement of the global statistical system. They compile and dissiminate global statistical information, develop standards and norms for statistical activities, and support countries’ efforts to strengthen their national statistical systems.
UN Comtrade Database: UN COMTRADE is the pseudonym for United Nations International Trade Statistics Database. It contains well over 3 billion data records since 1962 and is available publicly on the internet. In addition, it offers public and premium data API for easier integration/download. Time series of data for reporter countries starts as far back as 1962 and goes up to the most recent completed year. Current data is published annually in the International Trade Statistics Yearbook.
UNdata: UNdata is a web-based data service providing access to a variety of statistical resources compiled by the United Nations (UN) statistical system and other international agencies. Th UNdata contains 22 databases presenting various topics. Here is a sample of published databases:
- Energy statistics Database
- Environment Statistics Database
- Industrial Commodity Statistics Database
- International Financial Statistics
- World Tourism Data These data are produced from more than 20 international statistical sources compiled by the UN statistical system and other international agencies: Food and Agriculture Organization, International Labour Organization, International Monetary Fund, The World Bank, UNESCO Institute for Statistics, United Nations Children’s Fund, World Meteorological Organization, World Tourism Organization…
The UNESCO Institute for Statistics: The UNESCO Institute for Statistics (UIS) is the official and trusted source of internationally-comparable data on education, science, culture and communication. The UIS provides free access to data for all UNESCO countries and regional groupings from 1970 to the most recent year available. Databases are accessible via: data rowser, bulk data download service and API. Data is organized in different themes: Education (out-of-school childre, literacy, financial resources in education…), SDG 4 (sustaiable development goal indicators), equity, science and innovation, culture (culture employement, feature films, international trade in cultural goods…), communication and information, demographic and socio-economic.
Sustainable Development Goals: The Sustainable Development Goals (SDGs) are a collection of 17 global goals designed to be a “blueprint to achieve a better and more sustainable future for all”. The SDGs, set in 2015 by the United Nations General Assembly and intended to be achieved by the year 2030.

SDG indicators
The Sustainable Development Goals are: No Poverty, Zero Hunger, Good Health and Well-being, Quality Education, Gender Equality, Clean Water and Sanitation, Affordable and Clean Energy, Decent Work and Economic Growth, Industry, Innovation, and Infrastructure, Reducing Inequality, Sustainable Cities and Communities, Responsible Consumption and Production, Climate Action, Life Below Water, Life On Land, Peace, Justice, and Strong Institutions, and Partnerships for the Goals.
The United Nations provide platform of the Global SDG Indicators Database. This platform provides access to data compiled through the UN System in preparation for the Secretary-General’s annual report on “Progress towards the Sustainable Development Goals”.
We can also explore these indicators by the mean of SDG Tracker: a free, open-access resource where users can track and explore global and country-level progress towards each of the 17 Sustainable Development Goals through interactive data visualizations.
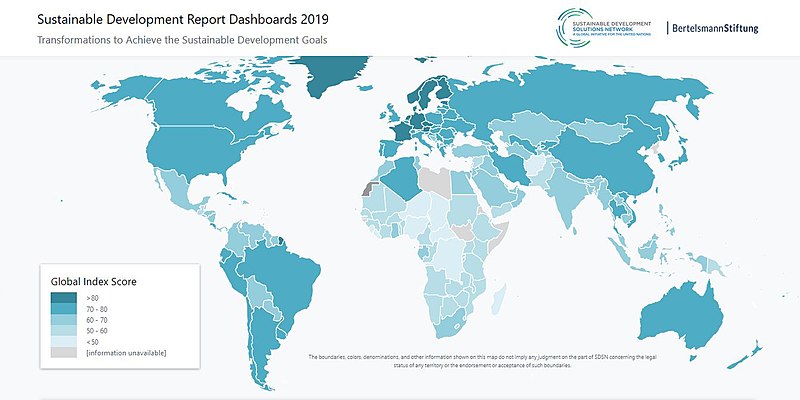
Sustainable Development Report Dashboards 2019
3.1.2 World Bank Open data
The World Bank Group is the largest development bank in the world and it is an observer at he United Nations Development Group. The World Bank collects and processes large amounts of data. These data have been made available to the public with different services and platforms.
Open Data Catalog: It is a listing of available World Bank datasets that we can browse by data type (Time Series, Microdata, and geospatial data) or by countries/regions.
- Time Series data: Datasets and Indicators level data that is a sequence of numbers collected at regular intervals over a period of time (Examples: Unemployement rate, labor force, urban population…)
- Microdata: Unit-level data obtained from sample surveys, censuses, and administrative systems (Examples: Employment And Welfare Survey, Demographic And Health Survey… )
- Geospatial: Data that has explicit geographic positioning information in vector or raster format (Examples: World - Terrain Elevation Above Sea Level, World Subnational Boundaries, World - Photovoltaic Power Potential…)
World Development Indicators: The World Development Indicators is a compilation of relevant, high-quality, and internationally comparable statistcs about global development and the fight against poverty. The database contains 1600 time series indicators for 217 economies and more than 40 country groups, with data for many indicators going back more than 50 years. Data is accessible by querying online th database using DataBank tool, by API or bulk downloads. The different datasets are categorized witin six themes: poverty and inequality, people, environment, eonomy, states and markets and global links. The following tables list some featured indicators provided in these themes.
- Poverty and shared prosperity: It presents indicators that measure progress toward the World Bank Group’s twin goals of ending extreme poverty by 2030 and promoting shared prosperity in every country in a sustainable manner.
library(knitr)
library(kableExtra)
kable(WDI_Poverty_and_Inequality[,-1]) %>%
kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive"),
font_size = 12) %>%
scroll_box(width = "100%", height = "400px")| Sub.themes | Featured.indicators | Indicator.description |
|---|---|---|
| Poverty rates at national poverty lines | Poverty headcount ratio at national poverty lines | The percentage of the population living below the national poverty lines. |
| Poverty gap at national poverty lines | The mean shortfall from the poverty lines (counting the nonpoor as having zero shortfall) as a percentage of the poverty lines | |
| Poverty rates at international poverty lines | Poverty headcount ratio at $1.90 a day | The percentage of the population living on less than $1.90 a day. |
| Distribution of income or consumption | GINI index | It measures the extent to whoch the distribution of income among individuals within an economy deviates frome a perfectly equal distribution. |
| Shared prosperity | Annualized average growth rate in per capita real survey mean consumption or income | The annualized average growth rate in per capita real consumption or income of the bottom 40% of the population |
| Survey mean consumption or income per capita, bottom 40% of population | Mean consumption or income per capita |
- People: It contains indicators for education, health, jobs, population, and gender that help capture the quality of people’s lives and provide a multidimensional portrait of the progress of societies.
kable(WDI_People[,-1]) %>%
kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive"),
font_size = 12) %>%
scroll_box(width = "100%", height = "400px")| Sub.themes | Featured.indicators | Indicator.description | |
|---|---|---|---|
| 7 | Population dynamics | Population, total | Counting of all residents of countries. |
| 8 | Population growth (annual %) | The exponential rate of growth of midyear population from year t-1 to t. | |
| 9 | Birth rate, crude | The number of live births occuring during the year, per 1000 population estimated at midyear. | |
| 10 | Death rate, crude | The number of deaths occuring during the year, per 1000 population estimated at midyear. | |
| 11 | Fertility rate, total | The number of children that would be born to a woman. | |
| 12 | Life expectancy at birth | The number of years a newborn infant would live if prevailing patterns of mortality at the time of its birth were to stay the same throughout its life. | |
| 13 | Education | Government expenditure on education | General government expenditure on education as a percentage of GDP. |
| 14 | School enrollment | Ratio of total enrollment (primary, secondary) | |
| 15 | Literacy rate, youth total | The percentage of people ages 15-24 who can both read and write. | |
| 16 | Labor | Labor force participation rate | The proportion of the population ages 15 and older that is economically active. |
| 17 | Emplyment by domain | The percentage of employment in agriculture, industry and services | |
| 18 | Employment to population ratio | The proportionof a country’s population that is employed. | |
| 19 | Health | Maternal mortality ratio | The number of women who die from pregnancy-related causes. |
| 20 | Mortality from CVD, cancer, diabetes or CRD between exact ages 30 and 70 | The percent of 30 y.o people who would die from these diseases. | |
| 21 | Mortality caused by road traffic injury | Road traffic fatal injury deaths per 100,000 population | |
| 22 | Gender | Ratio of female to male labor force participation rate | Dividing female labor force participation rate by male labor force participation rate |
- Environment: It shows how the state of the planet, as well as our use of natural resources, and the observed impacts. It contains indicators about agriculture, climate, energy use, water ressources…
kable(WDI_Environment[,-1]) %>%
kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive"),
font_size = 12) %>%
scroll_box(width = "100%", height = "300px")| Sub.themes | Featured.indicators | Indicator.description | |
|---|---|---|---|
| 23 | Agriculture | Agricultural land | The share of land area that is arable, under permanent crops, and under permanent pastures. |
| 24 | Climate | CO2 emissions | CO2 emission in tons per capita |
| 25 | PM2.5 air pollution | The average level of exposure of a nation’s population to concentrations of PM2.5. | |
| 26 | Average precipitation in depth | The ong-term average in depth (over space and time) of annual precipitation in the country (mm per year) | |
| 27 | Energy and mining | Energy intensity level of primary energy | The ratio between energy supply and gross domestic product. It is an indication of how much energy is used to produce one unit of economic output. |
| 28 | Renewable energy consumption | The share of renewables energy in total final enegy consumption | |
| 29 | Renewable electricity output | The share of electricity generated by renewable power plants in total electricity generated by all types of plants | |
| 30 | Environment | Forest area | Percentage of land under natural or planted stands of trees. |
| 31 | Total natural resources rents | The sum of oil rents, natural gas rents, coal rents, mineral rents, and forest rents. | |
| 32 | Urban and rural development | People using at least basic drinking water service | The percentage of peaple using at least basic water services |
| 33 | Water and sanitation | Renewable internal freshwater resources per capita | Internal renewable resources (river flows and groundwater from rainfall) |
- Economy: The indicators within the Economy section allow us to analyze various aspects of both national and global economic activity. As countries produce goods and services, and consume these domestically or trade internationally, economic indicators measure levels and changes in the size and structure of different economies, and identify growth and contractions.
kable(WDI_Economy[,-1]) %>%
kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive"),
font_size = 12) %>%
scroll_box(width = "100%", height = "400px")| Sub.themes | Featured.indicators | Indicator.description | |
|---|---|---|---|
| 34 | Growth and economic structure | GDP | The sum of gross value added by all resident producers in the economy. |
| 35 | GDP growth | Annual percentage growth rate of GDP at market prices. | |
| 36 | Agriculture, industry, manifacturing, services: value added | Annual growth rate for agricultural, industry, manifacturing, services value added based on constant local currency. | |
| 37 | Gross capital formation | Annual growth rate of gross capital formation | |
| 38 | Exports of goods and services | Annual growth rate of exports of goods and services | |
| 39 | Imports of goods and services | Annual growth rate of imports of goods and services | |
| 40 | Income and savings | GNI per capita, Atlas method | The gross national income divided by the midyear population. |
| 41 | Gross savings | Gross national income less total consumption, plus net transfers. | |
| 42 | Prices and terms of trade | Consumer price index | It reflects changes in the cost to the average consumer of acquiring a basket of goods and services |
| 43 | Labor and productivity | GDP per person employed | Gross domestic product divided by total employment in the economy. |
- States and markets: States and markets data measure the quality of the business environment, financial system development, transport infrastructure, ICT, science and technology, government, and policy performance.
kable(WDI_States_and_Markets[,-1]) %>%
kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive"),
font_size = 12) %>%
scroll_box(width = "100%", height = "400px")| Sub.themes | Featured.indicators | Indicator.description | |
|---|---|---|---|
| 44 | Business environment | Time required to start a business | The number of calendar days needed to complete the procedures to legally operate a business. |
| 45 | Financial access and stability | Depositors with commercial bank | The reported number of deposit account holders at commercial banks. |
| 46 | Government finance and taxes | Revenue, excluding grants | Cash receipts from taxes, social contributions, and other revenues. |
| 47 | Expense | Cash payments for operating activities of the government in providing goods and services. | |
| 48 | Military and fragile situations | Military expenditure | It includes all current and capital expenditures on the armed forces. |
| 49 | Armed forces personnel, total | Number of active military personnel. | |
| 50 | Infrastructure and communications | Air transport, passengers carried | It includes both domestic and international aircraft passengers |
| 51 | Mobile cellular subscriptions | Number of mobile cellular subscriptions | |
| 52 | Science and innovation | Research and development expenditure | Expenditure on research and development as a percent of GDP. |
| 53 | Scientific and technical journal articles | The number of sceintific and engineering articles published in sceintific journal. |
- Global links: The Global Links indicators provide an overview of the flows and associations that enable the world’s economy—and the economies of individual countries—to grow and expand. These indicators measure the size and direction of these flows, and document policy interventions such as tariffs, trade facilitation, and aid flows.
kable(WDI_Global_Links[,-1]) %>%
kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive"),
font_size = 12) %>%
scroll_box(width = "100%", height = "400px")| Sub.themes | Featured.indicators | Indicator.description | |
|---|---|---|---|
| 54 | External debt | External debt stocks, total | The sum of public and private nonguaranteed long-term debt and short term debt. |
| 55 | Trade | Merchandise trade | The sum of merchandise exports and imports divided by the value of GDP. |
| 56 | Refugees | Refugee population by country or territory of asylum | Number of refugee population |
| 57 | Tourism | International tourism, receipts | Expenditures by international inbound visitors (% of total exports) |
| 58 | Migration | Net migration | The net total migrants |
DataBank: DataBank is an analysis and visualisation tool that contains collections of time series data on a variety of topics. With this tool, we can create our own queries, generate tables, charts, and maps, and easily save, embed, and share them.
Open finances: Open Finances makes World Bank Group’s financials available for everybody to explore. They are orgnaized within different categories: loans and credits, financial reporting, shareholder equity, procurement, projects, budget…
Global Consumption Database: The Global Consumption Database is a one-stop source of data on household consumption patterns in developing countries. It is designed to serve a wide range of users—from researchers seeking data for analytical studies to businesses seeking a better understanding of the markets into which they are expanding or those they are already serving.
Microdata library: Provides acces to data collected through sample surveys of households, business establishments or other facilities.
3.1.3 World Health Organization
The Global Health Observatory data repository is an initiative of the World Health Organization to share data (through their website) on global health, including statistics by country and information about specific diseases and health measures. It provides access to over 1000 indicators on priority health topics including mortality and burden of diseases, the Millennium Development Goals (child nutrition, child health, maternal and reproductive health, immunization, HIV/AIDS, tuberculosis, malaria, neglected diseases, water and sanitation), non communicable diseases and risk factors, epidemic-prone diseases, health systems, environmental health, violence and injuries, equity among others.
We can use th WHO R package to collect the Global Health Observatory data.
## # A tibble: 6 x 3
## label display url
## <chr> <chr> <chr>
## 1 MDG_0000~ Infant mortality rate (probability~ https://www.who.int/data/gho/in~
## 2 MDG_0000~ Adolescent birth rate (per 1000 wo~ https://www.who.int/data/gho/in~
## 3 MDG_0000~ Contraceptive prevalence (%) https://www.who.int/data/gho/in~
## 4 MDG_0000~ Unmet need for family planning (%) https://www.who.int/data/gho/in~
## 5 MDG_0000~ Under-five mortality rate (probabi~ https://www.who.int/data/gho/in~
## 6 MDG_0000~ Median availability of selected ge~ https://www.who.int/data/gho/in~To find datasets based on specific thematics w can use regular expresssions for searching in existing datasets.
# searching for datasets related to "life expectancy"
codes[grepl("[Ll]ife expectancy", codes$display), ]## # A tibble: 4 x 3
## label display url
## <chr> <chr> <chr>
## 1 WHOSIS_00~ Life expectancy at birth (~ https://www.who.int/data/gho/indicator~
## 2 WHOSIS_00~ Healthy life expectancy (H~ https://www.who.int/data/gho/indicator~
## 3 WHOSIS_00~ Life expectancy at age 60 ~ https://www.who.int/data/gho/indicator~
## 4 WHOSIS_00~ Healthy life expectancy (H~ https://www.who.int/data/gho/indicator~Once, we identify a dataset code we can collect the data using get_data command.
## # A tibble: 6 x 7
## year gho country sex region publishstate value
## <dbl> <chr> <chr> <chr> <chr> <chr> <dbl>
## 1 2001 Life expectancy at birth (y~ Rwanda Both sex~ Africa Published 46.5
## 2 2002 Life expectancy at birth (y~ Rwanda Male Africa Published 46
## 3 2004 Life expectancy at birth (y~ Rwanda Female Africa Published 54.6
## 4 2004 Life expectancy at birth (y~ Rwanda Both sex~ Africa Published 51.9
## 5 2005 Life expectancy at birth (y~ Rwanda Male Africa Published 51
## 6 2007 Life expectancy at birth (y~ Rwanda Female Africa Published 62.2Now, we can plot the evolution of average life expectancy by region.
library(ggplot2)
df %>%
filter(sex == "Both sexes") %>%
group_by(region, year) %>%
summarise(value = mean(value)) %>%
ggplot(aes(x = year, y = value, color = region, linetype = region)) +
geom_line(size = 1) +
theme_light(9) +
labs(x = NULL, y = "Life expectancy at birth (years)\n",
linetype = NULL, color = NULL,
title = "Evolution of life expectancy (by region)\n")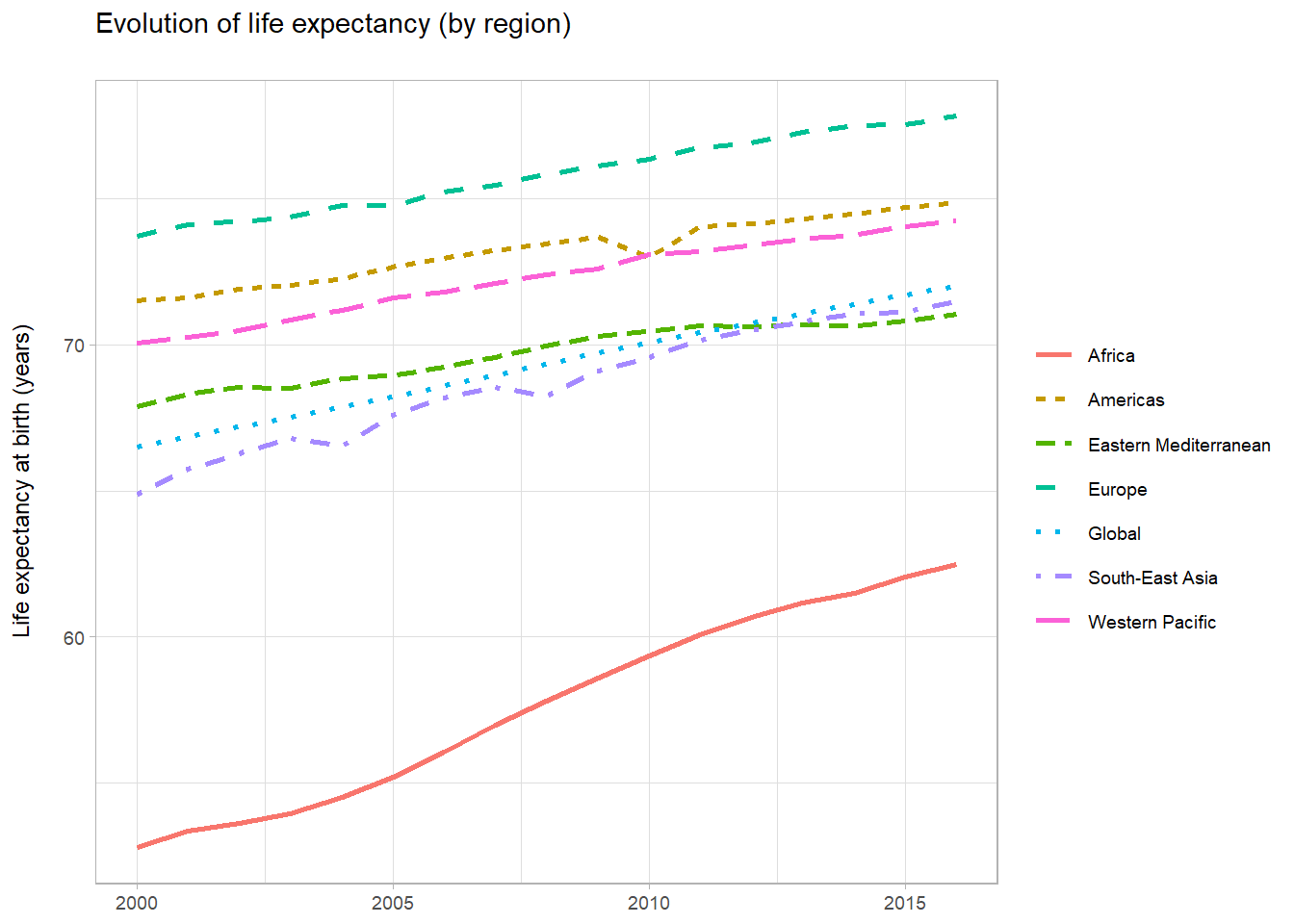
3.1.4 Food and Agriculture Organization of the United Nations
Food and Agriculture Organizationis responsible for the compilation, analysis and dissemination of a comprehensive variety of statistical data on food, agriculture and the sustainable management of natural resources. The organization provides free and unrestricted access to 16 major databases and produces publications with key statistical content covering different topics.
kable(FAO_opendata) %>%
kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive"),
font_size = 12) %>%
scroll_box(width = "100%", height = "500px")| Themes | Database | Description |
|---|---|---|
| Agriculture | FAOSTAT | It is the world’s most comprehensice statsitical database on food, agriculture, fisheries, forestry, natural resources management and nutrition. |
| Food and Agriculture Microdata | It provides an inventory of micro-level datasets collected through farm and household surveys which contain information related to agriculture, food security and nutrition. | |
| Food loss and Food waste database | It contains data and information from openly accessible reports and studies measuring food loss and waste across food products, stages of the value chain, and geographical areas. | |
| Fishery and aquaculture | FishStat Database | It provides comprehensive fisheries and aquaculture statistics, structured within data collections on a global and regional basis. |
| Forestry | Global Forest Resources Assessment Database | It provides essential information for understanding the extent of forest resources, their condition, management and uses. |
| Food prices and market information | Agricultural Market Information System Database | It provides market information on four grains particularly important in international food markets: wheat, maize, rice and soybeans. |
| Food Price Monitoring and Analysis | It contains latest information and analysis on domestic prices of basic foods mainly in developing countries, complementing FAO analysis on international markets. | |
| Economic, social and rural development | AIDmonitor | It aims to improve understanding of Official Development Assistance (ODA) funding flows in food and agriculture-related sectors. |
| Rural Livelihoods Information System | It provides indicators of agricultural income and rural livelihoods. | |
| Gender and Land Rights Database | A platform to highlight the major political, legal and cultural factors that influence the realisation of women’s land rights throughout the world. | |
| Food security and nutrition | International Network of Food Data Systems | INFOODS is a worldwide network of food composition experts aiming at improving the quality, availability, comparability, reliability and use of food composition data. |
| Global Individual Food consumption data | It provides microdata sets and ready-to-use indicators on individual food consumption, based on food consumption surveys conducted at national and subnational level. | |
| Natural genetic and biodiversity resources | AQUASTAT | It provides comprehensive information related to water resources, water uses and agricultural water management across the world. |
| Domestic Animal Diversity Information System | It provides access to searchable databases of breed-related information and photos and links to other online resources on livestock diversity. | |
| WIEWS | World onformation and early warning system on plant genetic resources for food and agriculture | |
| Sustainable Development Goals | SDG datasets | FAO’s Statistical Capacity Assessment survey for SDG Indicators provides insights about member countries’ national statistical systems in regard to their capacity to monitor and report the 21 SDG indicators: zero hunger, gender equality, clean water administration, responsable consumption and production, life below water, life onland… |
- Samples of FAO data:
Here is an example of an extraction of apple production data in France
kable(FAOSTAT_data[ ,c("Domain","Area","Element","Item","Year", "Unit","Value")]) %>%
kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive"),
font_size = 12) %>%
scroll_box(width = "100%", height = "600px")| Domain | Area | Element | Item | Year | Unit | Value |
|---|---|---|---|---|---|---|
| Crops | France | Production | Apples | 1961 | tonnes | 2142000 |
| Crops | France | Production | Apples | 1962 | tonnes | 5050000 |
| Crops | France | Production | Apples | 1963 | tonnes | 2581000 |
| Crops | France | Production | Apples | 1964 | tonnes | 3424000 |
| Crops | France | Production | Apples | 1965 | tonnes | 3675000 |
| Crops | France | Production | Apples | 1966 | tonnes | 2796000 |
| Crops | France | Production | Apples | 1967 | tonnes | 3846000 |
| Crops | France | Production | Apples | 1968 | tonnes | 3568000 |
| Crops | France | Production | Apples | 1969 | tonnes | 3377000 |
| Crops | France | Production | Apples | 1970 | tonnes | 3903000 |
| Crops | France | Production | Apples | 1971 | tonnes | 2967000 |
| Crops | France | Production | Apples | 1972 | tonnes | 2553000 |
| Crops | France | Production | Apples | 1973 | tonnes | 3265000 |
| Crops | France | Production | Apples | 1974 | tonnes | 2757000 |
| Crops | France | Production | Apples | 1975 | tonnes | 3104000 |
| Crops | France | Production | Apples | 1976 | tonnes | 2497000 |
| Crops | France | Production | Apples | 1977 | tonnes | 1687000 |
| Crops | France | Production | Apples | 1978 | tonnes | 3100000 |
| Crops | France | Production | Apples | 1979 | tonnes | 2464000 |
| Crops | France | Production | Apples | 1980 | tonnes | 2902000 |
| Crops | France | Production | Apples | 1981 | tonnes | 1437000 |
| Crops | France | Production | Apples | 1982 | tonnes | 1977000 |
| Crops | France | Production | Apples | 1983 | tonnes | 1965000 |
| Crops | France | Production | Apples | 1984 | tonnes | 2868000 |
| Crops | France | Production | Apples | 1985 | tonnes | 2349000 |
| Crops | France | Production | Apples | 1986 | tonnes | 2738000 |
| Crops | France | Production | Apples | 1987 | tonnes | 2388000 |
| Crops | France | Production | Apples | 1988 | tonnes | 2582000 |
| Crops | France | Production | Apples | 1989 | tonnes | 2340000 |
| Crops | France | Production | Apples | 1990 | tonnes | 2326000 |
| Crops | France | Production | Apples | 1991 | tonnes | 1283211 |
| Crops | France | Production | Apples | 1992 | tonnes | 2371861 |
| Crops | France | Production | Apples | 1993 | tonnes | 2050983 |
| Crops | France | Production | Apples | 1994 | tonnes | 2157952 |
| Crops | France | Production | Apples | 1995 | tonnes | 2063809 |
| Crops | France | Production | Apples | 1996 | tonnes | 1980069 |
| Crops | France | Production | Apples | 1997 | tonnes | 2018979 |
| Crops | France | Production | Apples | 1998 | tonnes | 1765375 |
| Crops | France | Production | Apples | 1999 | tonnes | 2133296 |
| Crops | France | Production | Apples | 2000 | tonnes | 2130274 |
| Crops | France | Production | Apples | 2001 | tonnes | 1882109 |
| Crops | France | Production | Apples | 2002 | tonnes | 1995306 |
| Crops | France | Production | Apples | 2003 | tonnes | 1721662 |
| Crops | France | Production | Apples | 2004 | tonnes | 1800177 |
| Crops | France | Production | Apples | 2005 | tonnes | 1829166 |
| Crops | France | Production | Apples | 2006 | tonnes | 1679328 |
| Crops | France | Production | Apples | 2007 | tonnes | 1781947 |
| Crops | France | Production | Apples | 2008 | tonnes | 1701752 |
| Crops | France | Production | Apples | 2009 | tonnes | 1729615 |
| Crops | France | Production | Apples | 2010 | tonnes | 1751269 |
| Crops | France | Production | Apples | 2011 | tonnes | 1762640 |
| Crops | France | Production | Apples | 2012 | tonnes | 1306333 |
| Crops | France | Production | Apples | 2013 | tonnes | 1688158 |
| Crops | France | Production | Apples | 2014 | tonnes | 1847551 |
| Crops | France | Production | Apples | 2015 | tonnes | 1968628 |
| Crops | France | Production | Apples | 2016 | tonnes | 1823123 |
| Crops | France | Production | Apples | 2017 | tonnes | 1695949 |
| Crops | France | Production | Apples | 2018 | tonnes | 1737412 |
## [1] Apples
## Levels: Apples## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 1283211 1786504 2131785 2349757 2752250 5050000
3.1.5 The World Resources Institute
World Resources Institute (WRI) is a global research organization that spans more than 60 countries. Its mission consists of promoting environmental sustainability and human health and well-being. WRI provides open access to reliable data related to global environment issues (forests monitoring, climate change, water scarcity…). In addition, WRI produces maps, charts, and visual resources based on their datasets.
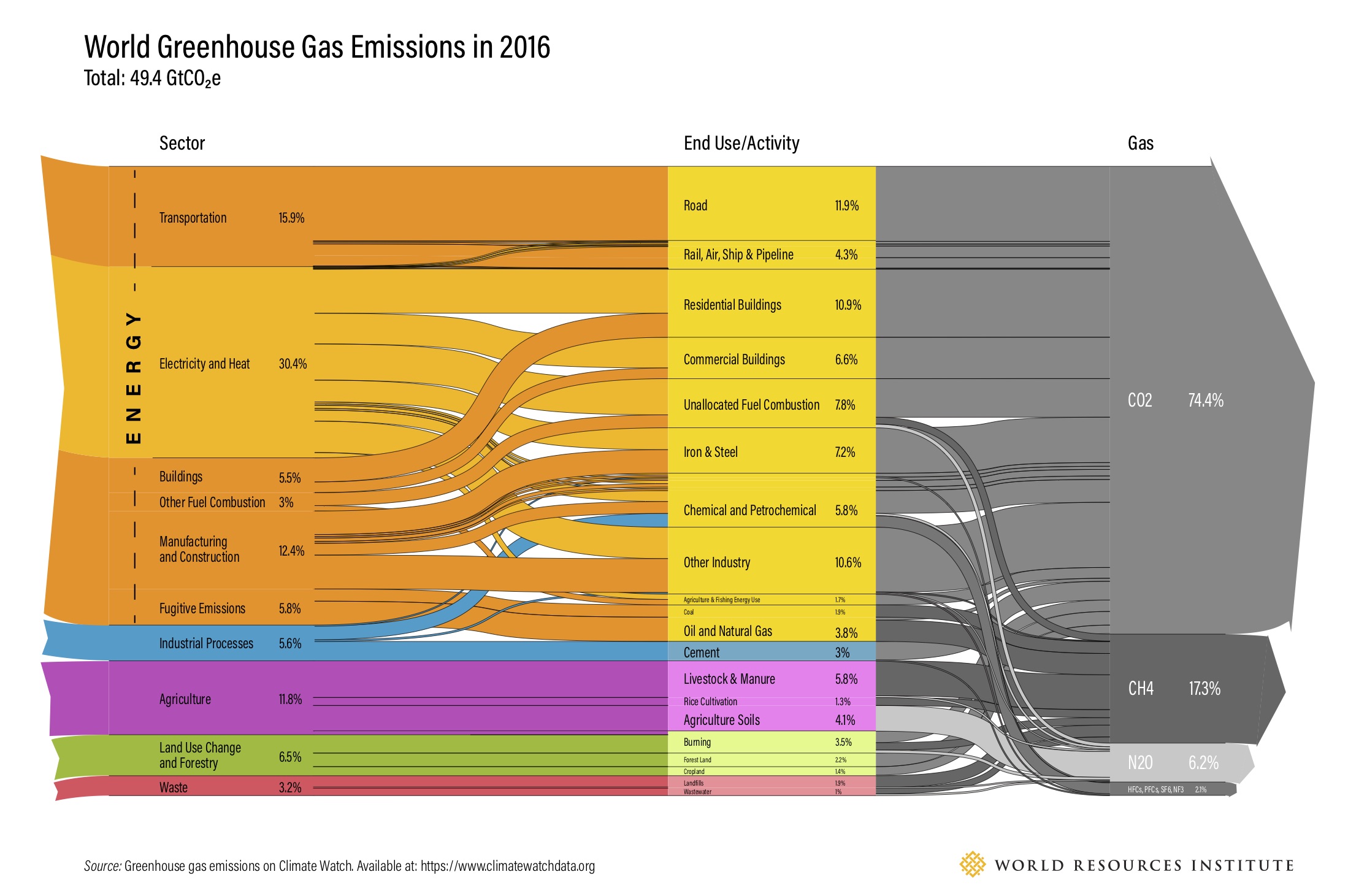
WOrld Greenhouse Gas EMission in 2016 (WRI)
- Water, peace and security: The Water, Peace, and Security tool is a data platform that help identify water-related security risks, and allow stakeholders to take action at an early stage.
- Energy Access Explorer: The Energy Access Explorer is an online, open-source, interactive platform that uses mapping to visualize the state of energy access in unserved and underserved areas. It analyzes credible and public data to make the connection between the demand and supply of energy.
- Global Forest Watch: The Global Forest Watch iis an online platform that provides data and tools for monitoring forests. By harnessing cutting-edge technology, GFW allows anyone to access near real-time information about where and how forests are changing around the world.
- Resource Watch: Resource Watch is an open data visualization platform with over 200 available data sets on topics ranging from climate change to human migration, deforestation to air quality, agriculture to energy and much more.
- Climate Watch: Climate Watch is an online platform designed to empower policymakers, researchers, media and other stakeholders with the open climate data, visualizations and resources they need to gather insights on national and global progress on climate change.
- PREPdata: PREPdata is a free, open-source data platform that provides the accessible, curated data that decision-makers need to analyze vulnerability and build climate resilience.
- Forest Atlases: Forest Atlases are online platforms that help countries better manage their forest resources by combining government data with the latest forest monitoring technology.
- LandMark: LandMark is the first online, interactive global platform to provide precise maps and other critical information on lands that are collectively held and used by Indigenous Peoples and local communities.
- Aqueduct: Aqueduct enable users to measure, map, and mitigate water risks around the world with its open-source, and high-resolution platform. It uses multiple data layers to display water risks at any given location.
3.1.6 Earth Observation data
Remote sensing is a technology that aims to observe and study the Earth systems, and their dynamics. Data related to remote sensing, specifically satellite images, have a purpose to observe and study the Earth from space; its land surface, the oceans and the atmosphere. Earth observation data can be acquired through different public and private channels. Free of cost data is generally provided by public agencies. Here is a list of the main providers of open earth observation data:
European Space Agency (ESA): The European Space Agency is an intergovernmental organisation dedicated to the exploration of space. It manages Copernicus Earth Observation program that aims at chieving a global, continuous, autonomous, high quality, wide range Earth observation capacity. The data and information produced in the framework Copernicus are made available free-to-charge all its users and the public. The ESA different provides tools to download, visualize and process earth observation data.
United States Geological Survey (USGS): The USGS is a scientific agency of the United STates government studying the the landscape of the United States, its natural resources, and the natural hazards that threaten it. It operates the landsat program with the NASA. Landsat is the longest-running enterprise for acquisition of satellite imagery of Earth. Landsat data products held in the USGS archives can be searched and downloaded at no charge from a variety of sources
National Aeronautics and Space Administration (NASA): The NASA is an independant agency of the United States Federal Government responsible for the civilian space program. NASA promotes the full and open sharing of all its data to research and applications communities, private industry, academia, and the general public by the mean of their Earth Observing System Data and Information System (EOSDIS). They provide different tools and products for seraching, using and visualizing remote sensing data:
Here is an example of visualizing downloaded Landsat data:
library(raster)
library(rgdal)
# Blue
b2 <- raster('data/rs/LC08_044034_20170614_B2.tif')
# Green
b3 <- raster('data/rs/LC08_044034_20170614_B3.tif')
# Red
b4 <- raster('data/rs/LC08_044034_20170614_B4.tif')
# Near Infrared (NIR)
b5 <- raster('data/rs/LC08_044034_20170614_B5.tif')
landsatRGB <- stack(b4, b3, b2)
plotRGB(landsatRGB, axes = TRUE, stretch = "lin", main = "Landsat True Color Composite")
3.1.7 Other resources
In addition to the previously cited organisations and services , plenty of other initiatives and services are providing and promoting the collection and usage of open data in a world wide scale.
- Our World in data: Our World in data is a collaborative project developed by reserachers at the University of Oxford and the non profit organization “Global Exhange Data Lab” to publish open data and statistics covering various world developement indicators. The website contains different articles based on open data and describing topics like: health, demographic change, food, agriuculture, energy, environment…
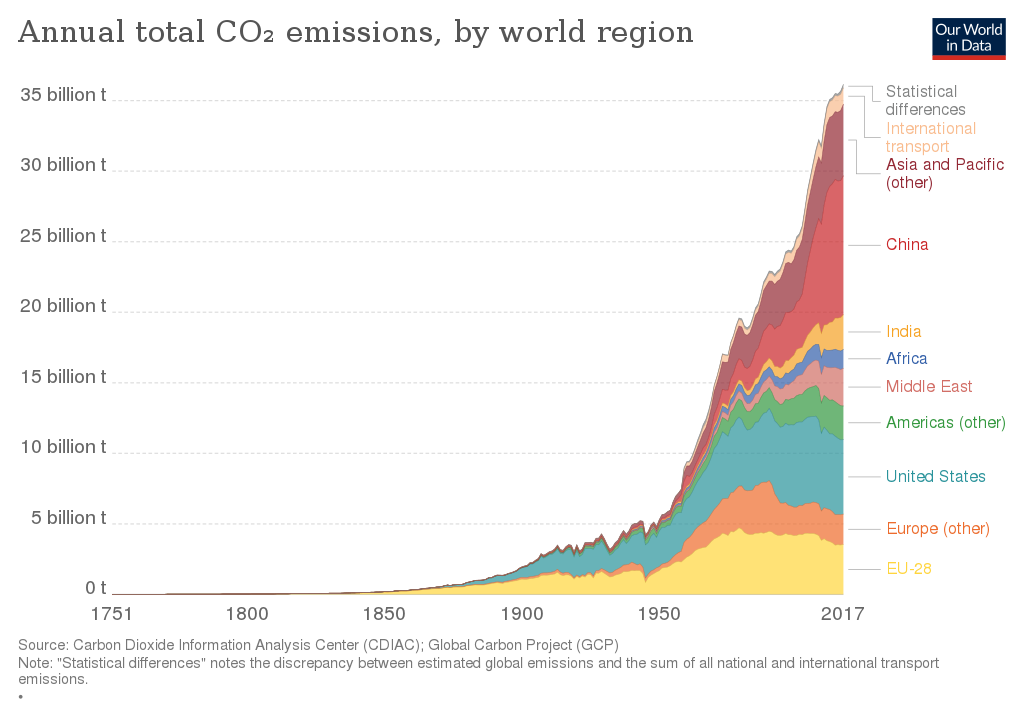
Global CO2 emissions by world region since 1750 (Our World In Data)
- Open knowledge FOundation (OKF): Open knowledge FOundation is a global, non-profit network that promotes and shares information at no charge, including both content and data.
- Comprehensive Knowledge Archive Network (CKAN): Open knowledge FOundation maintains the COmprehensive Knowledge Archive Network (CKAN) which is an open- source open data portal for the storage and distribution of open data. CKAN is used by differentnational and local governments such as: US data gov, european data portal, open data swiss, canadian data gov… Once the data is published, users can use its faceted search features to browse and find the data they need, and preview it using maps, graphs and tables – whether they are developers, journalists, researchers, NGOs, citizens, or even your own staff.
- GLobal Open Index: The Global Open Data Index (GODI) is the annual global benchmark for publication of open government data, run by the Open Knowledge Network.
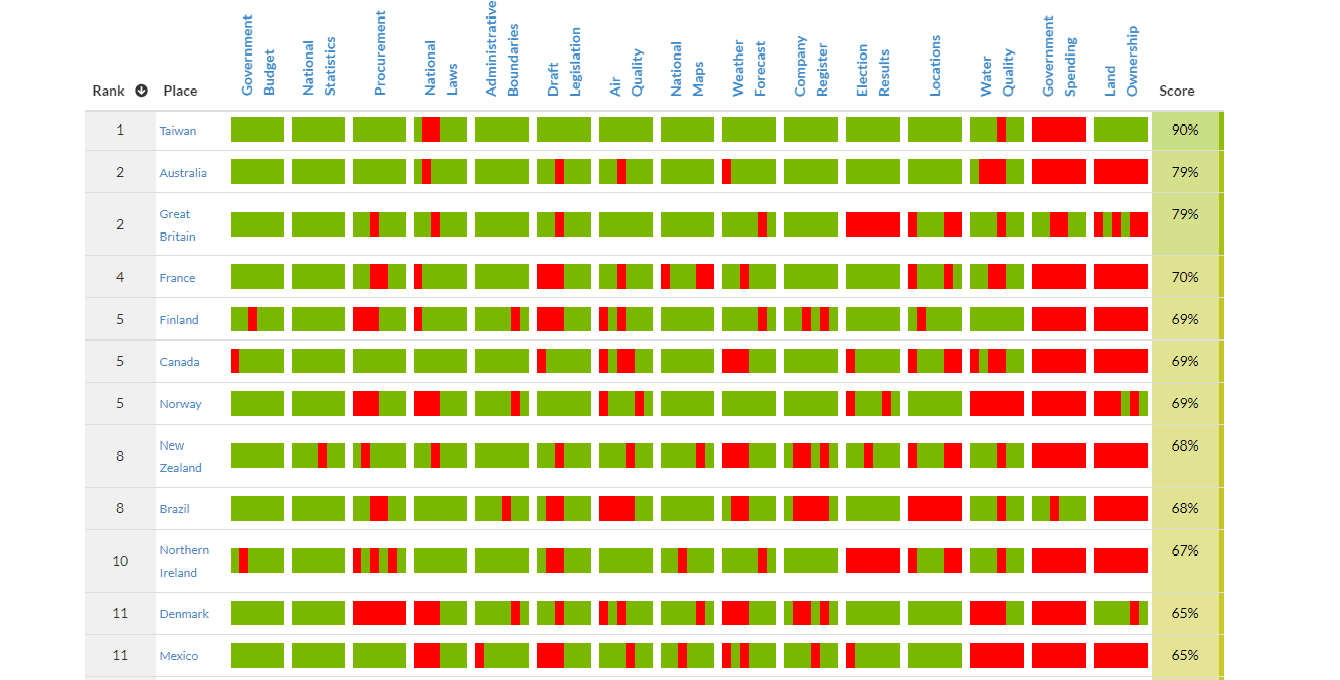
Open Data Index by country/thematic
- DBnomics: DBnomics is an oen platform aggregating global economic data and providing direct access to these data via one API. Examples of data provides: European Central Bank, Eurostat, Internationa Monetary Fund, International Labour Organization, WOrld Bank…
3.2 Tools
3.2.1 Extracting World Bank Data
There are different R and Python libraries providing access to World Bank data. We will test two of them in this chapter: WDI and Wbstats.
3.2.1.1 WDI
- Maternal mortality ratio
The WDI library provides easy access to the WorldBank open data. We can use the command WDIsearch for looking up an indicator.
## indicator
## [1,] "SH.STA.MMRT.NE"
## [2,] "SH.STA.MMRT"
## name
## [1,] "Maternal mortality ratio (national estimate, per 100,000 live births)"
## [2,] "Maternal mortality ratio (modeled estimate, per 100,000 live births)"
## description
## [1,] "Maternal mortality ratio is the number of women who die from pregnancy-related causes while pregnant or within 42 days of pregnancy termination per 100,000 live births."
## [2,] "Maternal mortality ratio is the number of women who die from pregnancy-related causes while pregnant or within 42 days of pregnancy termination per 100,000 live births. The data are estimated with a regression model using information on the proportion of maternal deaths among non-AIDS deaths in women ages 15-49, fertility, birth attendants, and GDP."
## sourceDatabase
## [1,] "World Development Indicators"
## [2,] "World Development Indicators"
## sourceOrganization
## [1,] "UNICEF, State of the World's Children, Childinfo, and Demographic and Health Surveys."
## [2,] "WHO, UNICEF, UNFPA, World Bank Group, and the United Nations Population Division. Trends in Maternal Mortality: 1990 to 2015. Geneva, World Health Organization, 2015"Once we get the label of the desired indicator, we can use the command WDI() to extract the data by specifying the indicator name, the list of countries, and the sart/end dates.
df <- data.frame(
WDI(country = c("US",
"BR",
"ZA"),
indicator = "SH.STA.MMRT",
start = 2005,
end = 2015,
extra = TRUE))
head(df)## iso2c country SH.STA.MMRT year iso3c region capital
## 1 BR Brazil 63 2015 BRA Latin America & Caribbean Brasilia
## 2 BR Brazil 62 2014 BRA Latin America & Caribbean Brasilia
## 3 BR Brazil 61 2013 BRA Latin America & Caribbean Brasilia
## 4 BR Brazil 60 2012 BRA Latin America & Caribbean Brasilia
## 5 BR Brazil 61 2011 BRA Latin America & Caribbean Brasilia
## 6 BR Brazil 65 2010 BRA Latin America & Caribbean Brasilia
## longitude latitude income lending
## 1 -47.9292 -15.7801 Upper middle income IBRD
## 2 -47.9292 -15.7801 Upper middle income IBRD
## 3 -47.9292 -15.7801 Upper middle income IBRD
## 4 -47.9292 -15.7801 Upper middle income IBRD
## 5 -47.9292 -15.7801 Upper middle income IBRD
## 6 -47.9292 -15.7801 Upper middle income IBRDWe can filter the extratced data using filter command of dplyr package.
## iso2c country SH.STA.MMRT year iso3c region capital
## 1 US United States 18 2015 USA North America Washington D.C.
## 2 US United States 16 2014 USA North America Washington D.C.
## 3 US United States 16 2013 USA North America Washington D.C.
## 4 US United States 16 2012 USA North America Washington D.C.
## 5 US United States 15 2011 USA North America Washington D.C.
## 6 US United States 15 2010 USA North America Washington D.C.
## longitude latitude income lending
## 1 -77.032 38.8895 High income Not classified
## 2 -77.032 38.8895 High income Not classified
## 3 -77.032 38.8895 High income Not classified
## 4 -77.032 38.8895 High income Not classified
## 5 -77.032 38.8895 High income Not classified
## 6 -77.032 38.8895 High income Not classifiedNow, we can use plotly library for producing an interactive visualization of the evolution of our indicator in different countries.
library(plotly)
trace_brazil = brazil$SH.STA.MMRT
trace_usa = usa$SH.STA.MMRT
dts = brazil$year
df.plot <- data.frame(dts, trace_brazil, trace_usa)
p1 <- plot_ly(df.plot,
x = ~dts,
y = ~trace_brazil,
name = "Brazil",
type = "scatter",
mode = "lines+markers") %>%
add_trace(y = ~trace_usa,
name = "USA",
type = "scatter",
mode = "lines+markers") %>%
layout(title = "Maternal mortality per 100,000 births",
xaxis = list(title = "Year",
zeroline = FALSE),
yaxis = list(title = "Count",
zeroline = FALSE))
p1- GDP Indicator
Since, there are a plenty of indicators related to gdp, we can use regular expressions for enhancing our search.
## indicator
## [1,] "6.0.GDPpc_constant"
## [2,] "NY.GDP.PCAP.PP.KD.87"
## [3,] "NY.GDP.PCAP.PP.KD"
## [4,] "NY.GDP.PCAP.KN"
## [5,] "NY.GDP.PCAP.KD"
## name
## [1,] "GDP per capita, PPP (constant 2011 international $) "
## [2,] "GDP per capita, PPP (constant 1987 international $)"
## [3,] "GDP per capita, PPP (constant 2011 international $)"
## [4,] "GDP per capita (constant LCU)"
## [5,] "GDP per capita (constant 2010 US$)"Now, let’s download the data corresponding to “GDP per capita (constant 2000 US$)”: the indicator name is NY.GDP.PCAP.KD. We can rename directly the indicator as gdp_per_capita.
dat = WDI(indicator=c("gdp_per_capita" = "NY.GDP.PCAP.KD"),
country=c('MX','CA','US'),
start=1960,
end=2012)
head(dat)## iso2c country gdp_per_capita year
## 1 CA Canada 48788.33 2012
## 2 CA Canada 48466.85 2011
## 3 CA Canada 47450.32 2010
## 4 CA Canada 46542.90 2009
## 5 CA Canada 48497.56 2008
## 6 CA Canada 48536.53 2007We can plot the data for the 3 selected countries
library(ggplot2)
ggplot(dat,
aes(year, gdp_per_capita, color=country)) +
geom_line() +
xlab('Year') +
ylab('GDP per capita')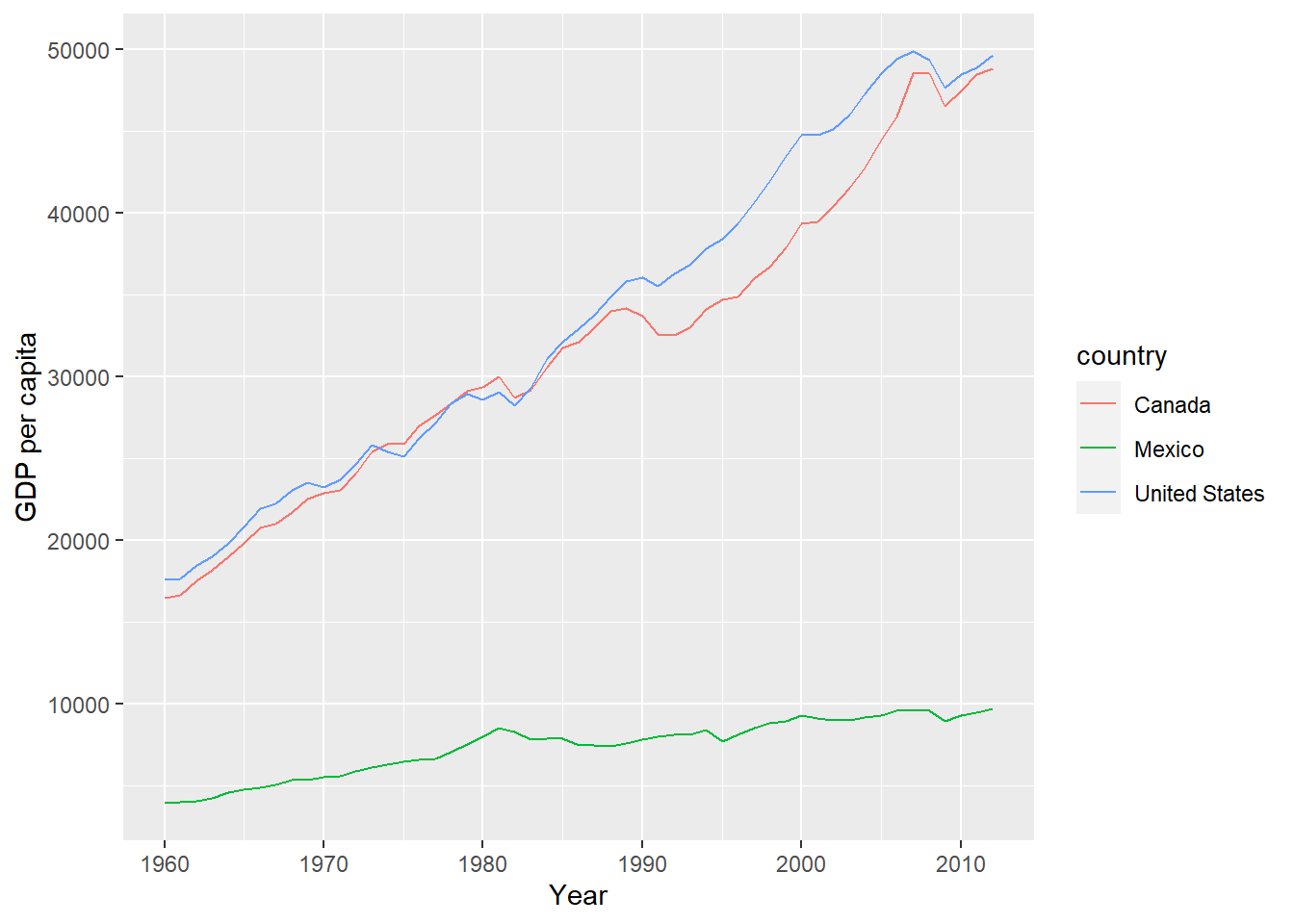
- Life expctancy:
Let’s find the IDs for the following indicators: life expectancy, GDP, and infant mortality.
## indicator name
## [1,] "NY.GDP.PCAP.KD" "GDP per capita (constant 2010 US$)"
## [2,] "NY.GDP.PCAP.CD" "GDP per capita (current US$)"## indicator
## "SP.DYN.LE00.IN"
## name
## "Life expectancy at birth, total (years)"## indicator
## [1,] "HF.DYN.IMRT.IN.Q5"
## [2,] "HF.DYN.IMRT.IN.Q4"
## [3,] "HF.DYN.IMRT.IN.Q3"
## [4,] "HF.DYN.IMRT.IN.Q2"
## [5,] "HF.DYN.IMRT.IN.Q1"
## [6,] "HF.DYN.IMRT.IN"
## [7,] "SP.DYN.IMRT.MA.IN"
## [8,] "SP.DYN.IMRT.IN"
## [9,] "SP.DYN.IMRT.FE.IN"
## name
## [1,] "Mortality rate, infant (per 1,000 live births): Q5 (highest)"
## [2,] "Mortality rate, infant (per 1,000 live births): Q4"
## [3,] "Mortality rate, infant (per 1,000 live births): Q3"
## [4,] "Mortality rate, infant (per 1,000 live births): Q2"
## [5,] "Mortality rate, infant (per 1,000 live births): Q1 (lowest)"
## [6,] "Mortality rate, infant (per 1,000 live births)"
## [7,] "Mortality rate, infant, male (per 1,000 live births)"
## [8,] "Mortality rate, infant (per 1,000 live births)"
## [9,] "Mortality rate, infant, female (per 1,000 live births)"Now we download the data
wdi_dat <- WDI(indicator = c("GDP" = "NY.GDP.PCAP.KD",
"life_expectancy" = "SP.DYN.LE00.IN",
"infant_mortality" = "SP.DYN.IMRT.IN"),
start = 1960, end = 2015,
extra = TRUE)
head(wdi_dat)## iso2c country year GDP life_expectancy infant_mortality iso3c region
## 1 1A Arab World 1960 NA 46.54691 NA ARB Aggregates
## 2 1A Arab World 1965 NA 49.49648 NA ARB Aggregates
## 3 1A Arab World 1966 NA 50.07295 NA ARB Aggregates
## 4 1A Arab World 1972 NA 53.40689 NA ARB Aggregates
## 5 1A Arab World 1973 NA 54.01585 NA ARB Aggregates
## 6 1A Arab World 1961 NA 47.14162 NA ARB Aggregates
## capital longitude latitude income lending
## 1 Aggregates Aggregates
## 2 Aggregates Aggregates
## 3 Aggregates Aggregates
## 4 Aggregates Aggregates
## 5 Aggregates Aggregates
## 6 Aggregates AggregatesWe can remove the entries with aggregated regional values
Let’s plot the distribution of infant mortality and GDP levels
library(ggplot2)
ggplot(subset(wdi_dat, year == 2008),
aes(x = GDP, y = infant_mortality)) + geom_point()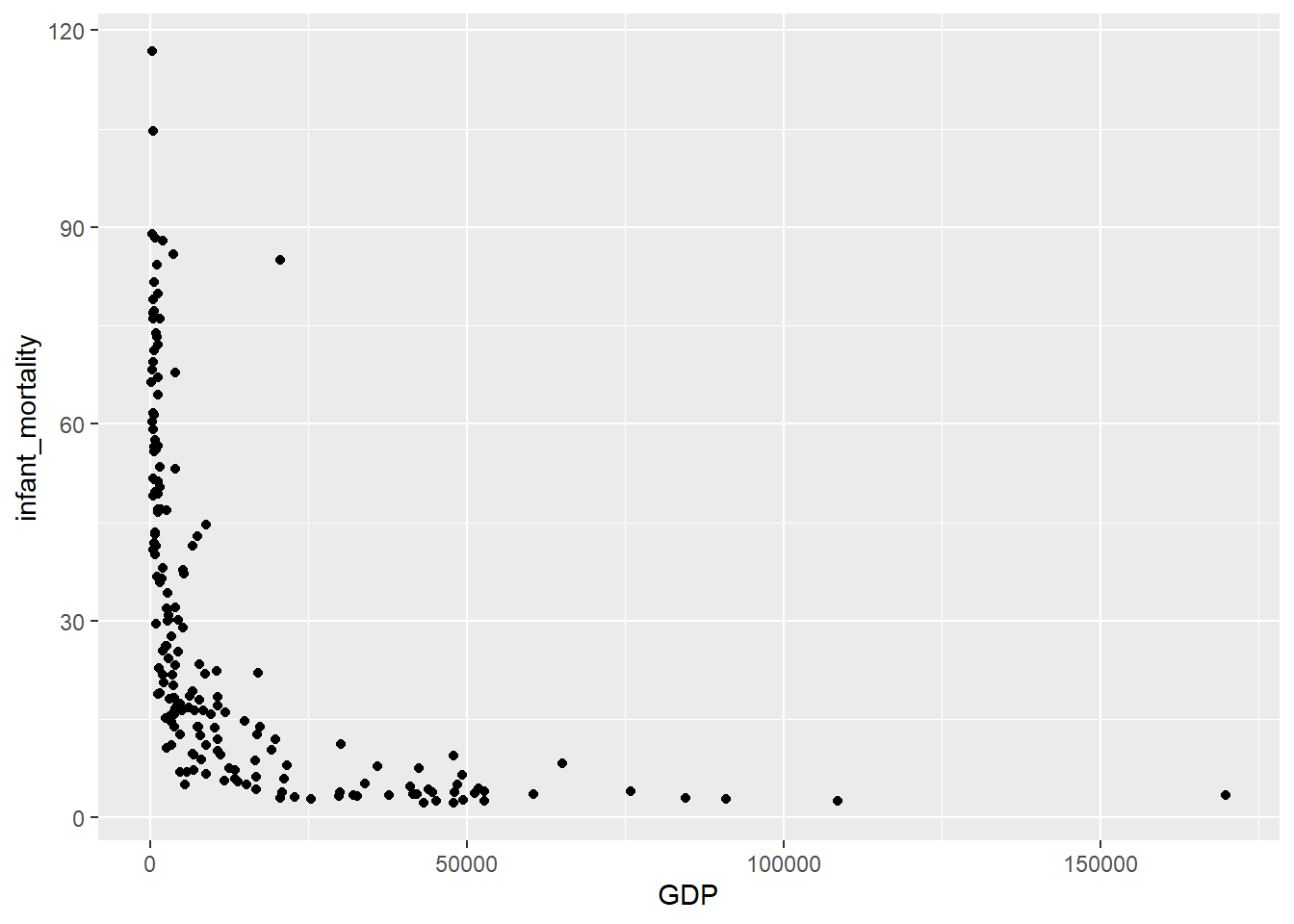
We can compare poverty in America with some world’s poor country, we can reproduce the graph presented by the Stanford Center on Poverty & Inequality article
# select countries
country_list = c("United States", "Rwanda", "Mongolia", "Pakistan", "Lao PDR", "Bhutan",
"Malaysia", "Brazil", "Ireland", "Japan", "Sweden", "Netherlands")
# subset data for the listed countries
lifexp_countries <- subset(wdi_dat,
country %in% country_list)
# plot data
ggplot(subset(lifexp_countries, year == "2008"),
aes(x = GDP, y = life_expectancy, color = country == "United States")) +
geom_point() +
geom_text(aes(label = country), size=3, nudge_y = 0.4) +
scale_x_continuous(limits = c(0, 70000))
We can follow the evoltion of these indicators in the selected countries using an interactive graph
3.2.1.2 Wbstats
Like WDI package, the wbstats library provide an interface for querying the World Bank API. In this section, we present some examples of using different commands for downloading and manipulating the world bank data.
wbstats provides a cached version of world bank data called wb_cachelist
## List of 7
## $ countries :'data.frame': 304 obs. of 18 variables:
## $ indicators :'data.frame': 16978 obs. of 7 variables:
## $ sources :'data.frame': 43 obs. of 8 variables:
## $ datacatalog:'data.frame': 238 obs. of 29 variables:
## $ topics :'data.frame': 21 obs. of 3 variables:
## $ income :'data.frame': 7 obs. of 3 variables:
## $ lending :'data.frame': 4 obs. of 3 variables:# We can use updated data and last ersions of indicators by saving the list returned from `wbcache`
new_cache <- wbcache()We use the command wbsearch for seraching the indicators based on regular expressions and text patterns
# 'poverty' OR 'unemployment' OR 'employment'
povemply_vars <- wbsearch(pattern = "poverty|unemployment|employment")
head(povemply_vars)## indicatorID
## 35 WP15177.9
## 36 WP15177.8
## 37 WP15177.7
## 38 WP15177.6
## 39 WP15177.5
## 40 WP15177.4
## indicator
## 35 Received government transfers in the past year, income, richest 60% (% ages 15+) [w2]
## 36 Received government transfers in the past year, income, poorest 40% (% ages 15+) [w2]
## 37 Received government transfers in the past year, secondary education or more (% ages 15+) [w2]
## 38 Received government transfers in the past year, primary education or less (% ages 15+) [w2]
## 39 Received government transfers in the past year, older adults (% ages 25+) [w2]
## 40 Received government transfers in the past year, young adults (% ages 15-24) [w2]we download the data with wb() command. We can specify a subset of countries
# Population, total
# country values: iso3c, iso2c, regionID, adminID, incomeID
pop_data <- wb(country = c("ABW","AF", "SSF", "ECA", "NOC"),
indicator = "SP.POP.TOTL", startdate = 2000, enddate = 2018)
head(pop_data)## iso3c date value indicatorID indicator iso2c country
## 1 ABW 2018 105845 SP.POP.TOTL Population, total AW Aruba
## 2 ABW 2017 105366 SP.POP.TOTL Population, total AW Aruba
## 3 ABW 2016 104872 SP.POP.TOTL Population, total AW Aruba
## 4 ABW 2015 104341 SP.POP.TOTL Population, total AW Aruba
## 5 ABW 2014 103774 SP.POP.TOTL Population, total AW Aruba
## 6 ABW 2013 103159 SP.POP.TOTL Population, total AW Arubawe can download data with multiple indicators in a long data format or a wide formar by specifying the parameter return_wide = TRUE
pop_gdp_wide <- wb(country = c("US", "NO"),
indicator = c("SP.POP.TOTL", "NY.GDP.MKTP.CD"),
startdate = 1971, enddate = 1971,
return_wide = TRUE)
head(pop_gdp_wide)## iso3c date iso2c country NY.GDP.MKTP.CD SP.POP.TOTL
## 1 NOR 1971 NO Norway 1.458311e+10 3903039
## 2 USA 1971 US United States 1.164850e+12 207661000When we don’t know the latest date for indicator availability in specified country, we can use the mrv command that returns the latest available entry.
## iso3c date value indicatorID indicator iso2c
## 1 USA 2018 100 EG.ELC.ACCS.ZS Access to electricity (% of population) US
## country
## 1 United StatesWhen we have missed values between actual observations, we can use the command gapfill to fill in these values with last observed ones
## iso3c date value indicatorID indicator
## 1 IND 2019 95.23586 EG.ELC.ACCS.ZS Access to electricity (% of population)
## 2 IND 2018 95.23586 EG.ELC.ACCS.ZS Access to electricity (% of population)
## 3 IND 2017 92.60000 EG.ELC.ACCS.ZS Access to electricity (% of population)
## 4 IND 2016 89.67192 EG.ELC.ACCS.ZS Access to electricity (% of population)
## 5 IND 2015 88.00000 EG.ELC.ACCS.ZS Access to electricity (% of population)
## 6 IND 2014 83.53472 EG.ELC.ACCS.ZS Access to electricity (% of population)
## 7 IND 2013 80.79154 EG.ELC.ACCS.ZS Access to electricity (% of population)
## 8 IND 2012 79.90000 EG.ELC.ACCS.ZS Access to electricity (% of population)
## 9 IND 2011 67.60000 EG.ELC.ACCS.ZS Access to electricity (% of population)
## 10 IND 2010 76.30000 EG.ELC.ACCS.ZS Access to electricity (% of population)
## iso2c country
## 1 IN India
## 2 IN India
## 3 IN India
## 4 IN India
## 5 IN India
## 6 IN India
## 7 IN India
## 8 IN India
## 9 IN India
## 10 IN IndiaWe can use the command POSIXct = TRUE in order to obtain datetime formats that make easier the manipulation and plotting time series data
pop_data <- wb(country = c("US","SSF", "ECA", "NOC"),
indicator = "SP.POP.TOTL",
startdate = 2000, enddate = 2018,
POSIXct = TRUE, freq = "M")
head(pop_data)## iso3c date value indicatorID indicator iso2c
## 1 ECA 2018 416944914 SP.POP.TOTL Population, total 7E
## 2 ECA 2017 414916897 SP.POP.TOTL Population, total 7E
## 3 ECA 2016 412611566 SP.POP.TOTL Population, total 7E
## 4 ECA 2015 410124886 SP.POP.TOTL Population, total 7E
## 5 ECA 2014 407578609 SP.POP.TOTL Population, total 7E
## 6 ECA 2013 405078322 SP.POP.TOTL Population, total 7E
## country date_ct granularity
## 1 Europe & Central Asia (excluding high income) 2018-01-01 annual
## 2 Europe & Central Asia (excluding high income) 2017-01-01 annual
## 3 Europe & Central Asia (excluding high income) 2016-01-01 annual
## 4 Europe & Central Asia (excluding high income) 2015-01-01 annual
## 5 Europe & Central Asia (excluding high income) 2014-01-01 annual
## 6 Europe & Central Asia (excluding high income) 2013-01-01 annualggplot(pop_data, aes(x = date_ct, y = value, colour = country)) + geom_line(size = 1) +
labs(title = "Total population", x = "Date", y = "Population")
3.2.2 Extracting DBnomics Data
DBnomics is an open-source project with the goal of aggregating the world’s economic data in one location, free of charge to the public. DBnomics covers hundreds of millions of series from international and national institutions (Eurostat, World Bank, IMF, …). We will use in this section the rdbnomics which is an R package providing access to DBnomics data series.
In order to get dbnomics data we have to specify a serie identifier (ids) defined by three values formatted in this way: provider_code/dataset_code/series/code. We can find these infrmation in the DBnomics and DBnomics API documentation. Here is an example of fetching unemployemet rate dataset (called ZUTN) from the AMECO provider.
library(rdbnomics)
library(data.table)
library(magrittr)
library(dplyr)
library(ggplot2)
# get two series of unemployement rate data (europe and danemark)
df = rdb(ids = c('AMECO/ZUTN/EA19.1.0.0.0.ZUTN', 'AMECO/ZUTN/DNK.1.0.0.0.ZUTN')) %>%
filter(!is.na(value))
head(df)## @frequency Country dataset_code
## 1 annual Euro area ZUTN
## 2 annual Euro area ZUTN
## 3 annual Euro area ZUTN
## 4 annual Euro area ZUTN
## 5 annual Euro area ZUTN
## 6 annual Euro area ZUTN
## dataset_name freq Frequency
## 1 Unemployment rate: total :- Member States: definition EUROSTAT a Annually
## 2 Unemployment rate: total :- Member States: definition EUROSTAT a Annually
## 3 Unemployment rate: total :- Member States: definition EUROSTAT a Annually
## 4 Unemployment rate: total :- Member States: definition EUROSTAT a Annually
## 5 Unemployment rate: total :- Member States: definition EUROSTAT a Annually
## 6 Unemployment rate: total :- Member States: definition EUROSTAT a Annually
## geo indexed_at original_period original_value period
## 1 ea19 2020-05-07 08:46:14 1997 11.5 1997-01-01
## 2 ea19 2020-05-07 08:46:14 1998 11 1998-01-01
## 3 ea19 2020-05-07 08:46:14 1999 10.2 1999-01-01
## 4 ea19 2020-05-07 08:46:14 2000 9.2 2000-01-01
## 5 ea19 2020-05-07 08:46:14 2001 8.4 2001-01-01
## 6 ea19 2020-05-07 08:46:14 2002 8.6 2002-01-01
## provider_code series_code
## 1 AMECO EA19.1.0.0.0.ZUTN
## 2 AMECO EA19.1.0.0.0.ZUTN
## 3 AMECO EA19.1.0.0.0.ZUTN
## 4 AMECO EA19.1.0.0.0.ZUTN
## 5 AMECO EA19.1.0.0.0.ZUTN
## 6 AMECO EA19.1.0.0.0.ZUTN
## series_name
## 1 Annually – (Percentage of active population) – Euro area
## 2 Annually – (Percentage of active population) – Euro area
## 3 Annually – (Percentage of active population) – Euro area
## 4 Annually – (Percentage of active population) – Euro area
## 5 Annually – (Percentage of active population) – Euro area
## 6 Annually – (Percentage of active population) – Euro area
## unit Unit value
## 1 percentage-of-active-population (Percentage of active population) 11.5
## 2 percentage-of-active-population (Percentage of active population) 11.0
## 3 percentage-of-active-population (Percentage of active population) 10.2
## 4 percentage-of-active-population (Percentage of active population) 9.2
## 5 percentage-of-active-population (Percentage of active population) 8.4
## 6 percentage-of-active-population (Percentage of active population) 8.6# plot
ggplot(df,
aes(x = period, y = value, color = series_name)) +
geom_line(size = 1.2) +
geom_point(size = 2) +
dbnomics()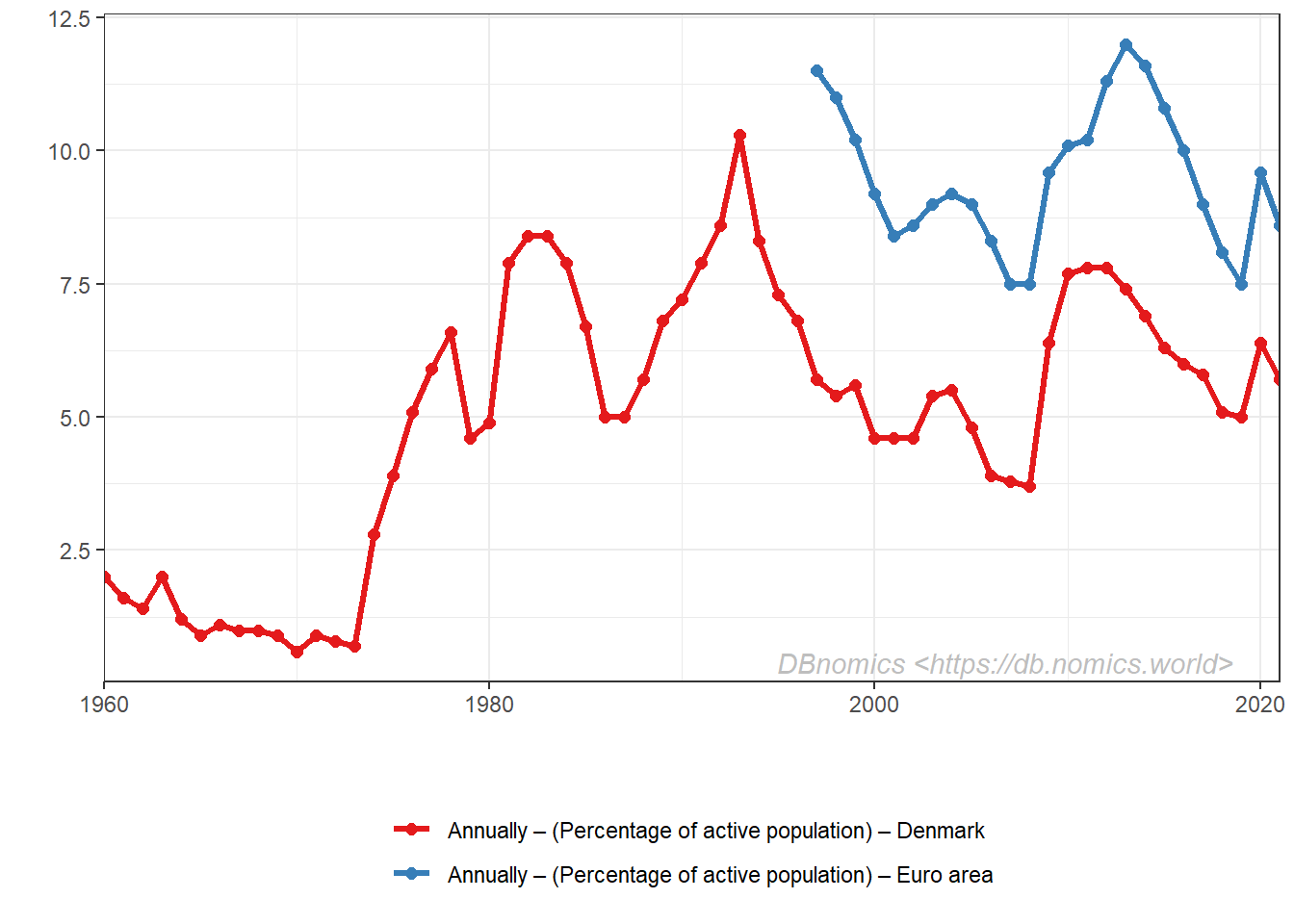
There is another way to get time series by using code mask notation. Here is an example of extracting the balance of payement data (BOP) from IMF provider.
# get data of France
df <- rdb('IMF', 'BOP', mask = 'A.FR.BCA_BP6_EUR') %>%
filter(!is.na(value))
unique(df$REF_AREA)## [1] "FR"# get data of france and spain
df <- rdb('IMF', 'BOP', mask = 'A.FR+ES.BCA_BP6_EUR') %>%
filter(!is.na(value))
unique(df$REF_AREA)## [1] "ES" "FR"# plot
ggplot(df, aes(x = period, y = value, color = series_name)) +
geom_line(size = 1.2) +
geom_point(size = 2) +
dbnomics()
We can extract data using directly the API link provided in DBnomics webstie.
df <- rdb(api_link = "https://api.db.nomics.world/v22/series?observations=1&series_ids=BOE/6008/RPMTDDC,BOE/6231/RPMTBVE") %>%
filter(!is.na(value))
ggplot(df, aes(x = period, y = value, color = series_name)) +
geom_line(size = 1.2) +
geom_point(size = 2) +
dbnomics()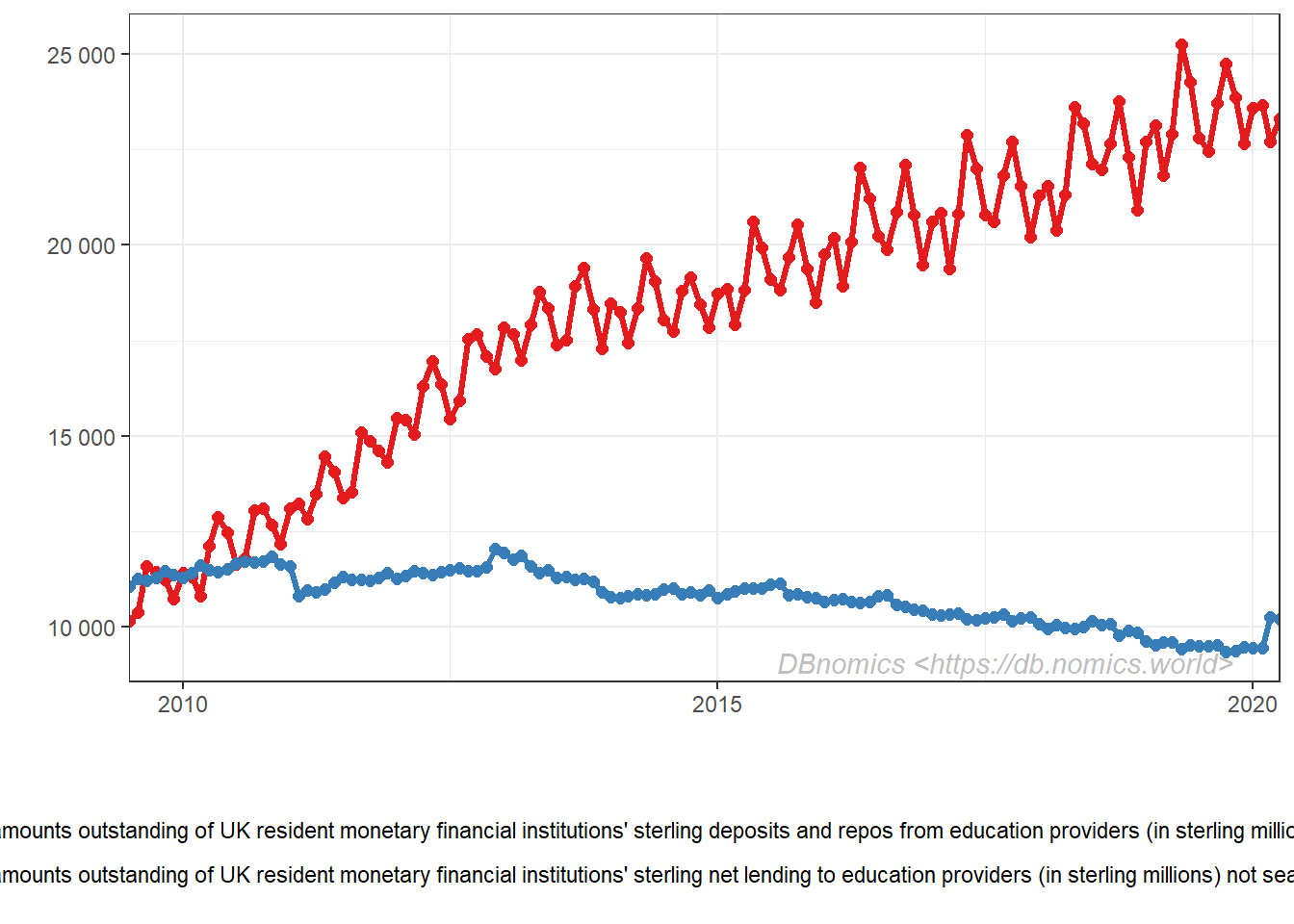
3.2.3 Other tools
We can find a plenty of other tools and libraries enabling the extraction of world scale open data from different sources. This article presents a complete overview of these tools.
- tidycensus: Load US Census Boundary and Attribute Data as ‘tidyverse’ and ‘sf’-Ready Data Frames
- IMFData: R Interface for International Monetary Fund(IMF) Data API
- OECD: Search and Extract Data from the OECD
- rWBclimate: R interface for the World Bank climate data
- getlandsat: Get Landsat 8 Data from Amazon Public Data Sets