Chapter 10 Document-term matrix
A document-term matrix is a mathematical matrix that describes the frequency of terms that occur in a collection of documents. In a document-term matrix:
- Rows correspond to documents in the collection and
- Columns correspond to terms
- Values contain the number of appearances of terms in the specified documents
10.1 COnverting DTM into dataframe
We will see how to transform a document-term matrix into a dataframe. We can find examples of DTM data by loading topicmodels package.
library(tm)
library(topicmodels)
library(quanteda)
data("AssociatedPress", package = "topicmodels")
AssociatedPress## <<DocumentTermMatrix (documents: 2246, terms: 10473)>>
## Non-/sparse entries: 302031/23220327
## Sparsity : 99%
## Maximal term length: 18
## Weighting : term frequency (tf)The loaded dataset contains 2246 documents and 10473 distinct terms. We notice that this DTM is 99% sparse (99% of document-word paris are zero). We can get the terms using Terms() function.
## [1] "aaron" "abandon" "abandoned" "abandoning" "abbott"
## [6] "abboud"In order to analyze the data, we should transform it inot dataframe. We can use tidy() function to do that.
## # A tibble: 302,031 x 3
## document term count
## <int> <chr> <dbl>
## 1 1 adding 1
## 2 1 adult 2
## 3 1 ago 1
## 4 1 alcohol 1
## 5 1 allegedly 1
## 6 1 allen 1
## 7 1 apparently 2
## 8 1 appeared 1
## 9 1 arrested 1
## 10 1 assault 1
## # ... with 302,021 more rowsOnce we have the data in a dataframe format, we can perform some analysis. Here is an example of applying sentiment analysis to evaluate the negative and positive terms in the collection.
# using "bing" database to attribute negative/positive attribute to terms
ap_sentiments = ap_td %>%
inner_join(get_sentiments("bing"), by = c(term = "word"))
ap_sentiments## # A tibble: 30,094 x 4
## document term count sentiment
## <int> <chr> <dbl> <chr>
## 1 1 assault 1 negative
## 2 1 complex 1 negative
## 3 1 death 1 negative
## 4 1 died 1 negative
## 5 1 good 2 positive
## 6 1 illness 1 negative
## 7 1 killed 2 negative
## 8 1 like 2 positive
## 9 1 liked 1 positive
## 10 1 miracle 1 positive
## # ... with 30,084 more rows# plot the results
library(ggplot2)
ap_sentiments %>%
count(sentiment, term, wt = count) %>%
ungroup() %>%
filter(n >= 200) %>%
mutate(n = ifelse(sentiment == "negative", -n, n)) %>%
mutate(term = reorder(term, n)) %>%
ggplot(aes(term, n, fill = sentiment)) +
geom_bar(stat = "identity") +
ylab("Contribution to sentiment") +
coord_flip()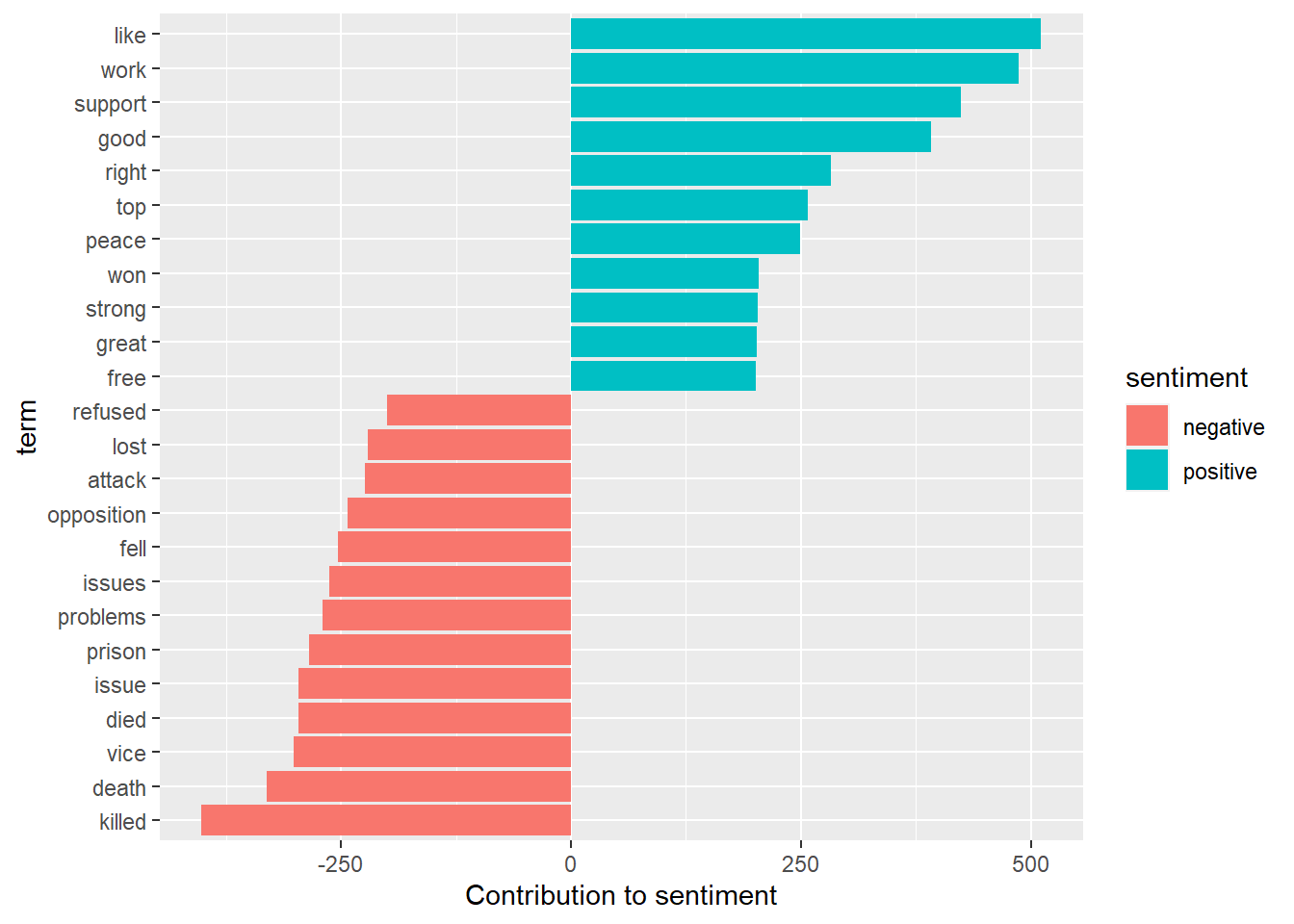
10.2 Generating Document-term matrix
Some algorithms may need document-term matrix as input. The cast_dtm function enable the generation of DTM structure from a dataframe.
## <<DocumentTermMatrix (documents: 2246, terms: 10473)>>
## Non-/sparse entries: 302031/23220327
## Sparsity : 99%
## Maximal term length: 18
## Weighting : term frequency (tf)We can also generate a Document-feature matrix by using the cast_dfm function
## Document-feature matrix of: 2,246 documents, 10,473 features (98.7% sparse).
## features
## docs adding adult ago alcohol allegedly allen apparently appeared arrested
## 1 1 2 1 1 1 1 2 1 1
## 2 0 0 0 0 0 0 0 1 0
## 3 0 0 1 0 0 0 0 1 0
## 4 0 0 3 0 0 0 0 0 0
## 5 0 0 0 0 0 0 0 0 0
## 6 0 0 2 0 0 0 0 0 0
## features
## docs assault
## 1 1
## 2 0
## 3 0
## 4 0
## 5 0
## 6 0
## [ reached max_ndoc ... 2,240 more documents, reached max_nfeat ... 10,463 more features ]